准备:
1.mongodb环境
2.编译工具:navicat
一.MongoDB数据库和集合基本操作
1.1文档
在MongoDB中,第一步也是创建数据库和集合。数据库用于存储所有集合,而集合又用于存储所有文档。这些文档将依次包含相关的“字段名”和“字段”值,我们如果使用MongoDB作为数据库存储信息,则信息都是写在文档中,我们对数据的增删改查操作也主要是在文档之中。
“文档”(Document)是 BSON 格式(一种类似于 JSON 的格式)的数据结构,它是 MongoDB 存储数据的基本单元。每个文档都是一个键值对的集合,其中的键(key)是字符串,值(value)可以是字符串、数字、数组、布尔值、日期、null、另一个文档,甚至是文档数组。
文档的特点:
- 自描述性:文档可以包含任意数量的字段,每个字段的值可以是不同的数据类型。
- 灵活的结构:在同一个集合中的不同文档可以有不同的结构,不需要像关系型数据库那样有固定的表结构。
- 层次结构:文档可以嵌套其他文档,形成层次结构。
文档的组成:
- 字段(Field):文档中的键值对,键是字符串,值可以是不同的数据类型。
- 值(Value):字段的值,可以是简单数据类型、数组或嵌套的文档。
下面的图展示了文档结构的例子。

文档的字段名分别为“ Employeeid”和“ EmployeeName”,字段值分别为“ 1”和“ Smith”,一堆文档将构成MongoDB中的一个集合。
序言:我将在下面讲述MongoDB的CRUDC操作,并一边示例演示操作,如果是还没学过的建议手敲下面的实现案例。
1.2数据库和集合的创建
(1)創建与使用数据库
语法格式:use 数据库名例如:use test #创建名为mongo的数据库
注意:
- 在“use”命令创建MongoDB中的数据库。如果数据库不存在,将创建一个新的数据库。
- 创建成功之后,MongoDB将自动切换到创建的数据库。
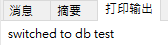
- 使用某个数据库也可使用该语法。比如当前我们有两个数据库test、student,若我们创建了一个名为data的数据库,则会自动切换到创建的data数据库,若我们需要使用test数据库,则我们只要编写代码 use test 即可切换到test数据库(下图为实现结果)。
(2) 创建集合
使用insert()创建集合/表
语法格式:db.集合名.insert(document)(document即为文档,操作即为增删改查,在后面会补充。)
创建集合的最简单方法是一条记录(不过是由字段名称和值组成的文档)插入到集合中。如果该集合不存在,则会创建一个新的集合。
操作示例代码:
db.Employee.insert //集合名字即为Employee,集合名可以根据情况自行书写
(
{ //{ }为插入的文档,其中的字段为要插入的文档内容
_id:'1001',
name:"夏东晖",
age:'24'
}
)代码说明:
上面的代码,表示通过使用“插入”命令,创建集合。
db.collection.find() //查看集合中的文档
执行结果:

2.数据库和集合的删除
2.1数据库的删除
语法格式: db.dropDatabase( )该操作是删除当前使用的数据库。如果我们不确定当前使用的数据库名,可以先使用 use 数据库名 先切换到要删除的数据库,然后再使用该语法进行删除。
操作实例:现在我有三个数据库 ‘data’、’db’、’test’
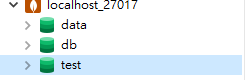
现在删除 ‘test’ 数据库
use test //切换使用test数据库
db.dropDatabase //删除当前数据库 test
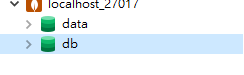
可以看到 ‘test’ 数据库已经被删除了。是不是比较简单呢?
2.2删除集合
语法格式:db.集合名.drop( )该操作是删除当前数据库下某个集合。
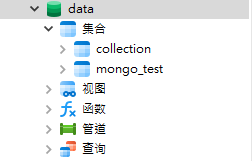
操作实例:当前使用的数据库为data ,创建两个集合collection、mongo_test(字段任意),然后删除名为collection的集合
步骤一:创建两个集合
db.collection.insert({
content:'这是一个测试'
})
db.mongo_test.insert({
_id:'1001',
content:'这是一个测试',
num:'100'
})我们在数据库即可看到两个集合生成
步骤二:删除collection集合
db.collection.drop()
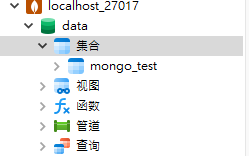
我们可以看到,集合collection在数据库被删除了。
二.集合的常见操作
2.1 插入文档(insert)
(1)插入一個文檔
语法格式:db.集合名.insert()插入一条记录只需要在insert()函数的括号中写入文档即可,上述集合创建时已经展示,下面继续叙述如何插入多条记录。
(2)使用数组插入多個文檔
语法格式:db.集合名.insert()“insert”命令也可以一次将多个文档插入到集合中。下面我们操作如何一次插入多个文档。
我们完成如下步骤即可,
1)创建一个JavaScript变量来保存文档数组
2)将具有字段名称和值的所需文档添加到变量
3)使用insert命令将文档数组插入集合中
示例:
#插入多条数据(多个文档) 用数组实现
var myStudent=[
//创建JavaScript变量名为myStudent
{ _id:'1002', //添加的文档写在{}中,多个文档用逗号分隔开
name:"李白",
age:'25'
},
{ _id:'1003',
name:"杜甫",
age:'26'
},
{ _id:'1004',
name:"李牧",
age:'27'
}
];
db.collection.insert(myStudent) #将变量写入到插入语句db.collection.find() #查看集合中的文档
执行结果:
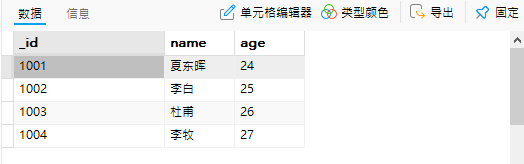
图 2-1
(3)以JSON格式打印
JSON是一种称为JavaScript Object Notation的格式,是一种规律存储信息,易于阅读的格式在Java或Python的实际开发中,也时常用到的是json格式文件。在如下的例子中,我们将使用JSON格式查看输出。
语法格式:数据库名.集合名.find( ).forEach(printjson)
示例:以图2-1的数据为例
//以json格式打印
db.collection.find().forEach(printjson)代码说明:
- 第一个更改是将对Each()调用的函数附加到find()函数。这样做是为了确保明确浏览集合中的每个文档。这样,您就可以更好地控制集合中每个文档的处理方式。
- 第二个更改是将printjson命令放入forEach语句。这将导致集合中的每个文档以JSON格式显示。
执行结果:
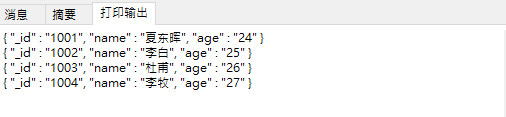
2.2 删除文档
(1)删除一个文档
要删除集合中匹配特定条件的第一个文档,可以使用:
db.集合名.remove(
{ },
{ justOne: true }
) 这里的 justOne: true 表示只删除一个文档(删除根据条件筛选出来的第一个文档)。
例如:删除collection集合中name为”John Doe”的第一个文档
db.collection.remove(
{ name: “John Doe” },
{ justOne: true }
)
删除一个文档还有另外一种写法:
db.集合名.deleteOne() 例如上述案例可写为
db.collection.deleteOne({ name: "John Doe" })(2)删除多个文档
要删除集合中所有匹配特定条件的文档,可以省略 justOne 选项或将其设置为 false。
db.集合名.remove(
{ },
{ justOne: false }
) 例如:删除collection集合中name为”John Doe”的所有文档
db.collection.remove(
{ name: "John Doe" }
)删除多个文档的另外一种写法:
db.集合名.deleteMany() 上述案例可写为:
db.collection.deleteMany({ name: "John Doe" })(3)删除所有文档
要删除集合中的所有文档,可以传递一个空的查询条件:
db.集合名.remove({});或者使用删除集合的方法删除所有的文档
db.集合名.drop()
实操案例:
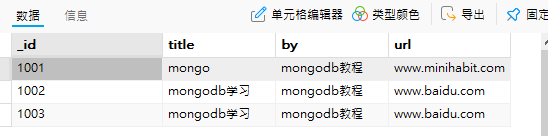
1.给当前使用的数据库创建集合student,插入三个文档定义字段名’_id’、’title’、’by’、’url’,字段值自定义。
2.删除第一个’by’为’mongodb教程’的第一个文档 。
3.删除’by’为’mongodb教程’的所有文档 。
//student集合插入文档
//插入多个文档使用数组,'[ ]'别遗忘
var document=[
{ _id:'1001',
title:'mongodb学习',
by:'mongodb教程',
url:'www.baidu.com'
},
{ _id:'1002',
title:'mongodb学习',
by:'mongodb教程',
url:'www.baidu.com'
},{ _id:'1003',
title:'mongodb学习',
by:'mongodb教程',
url:'www.baidu.com'
}
]
db.student.insert(document)//查看集合中的文档
db.student.find( )
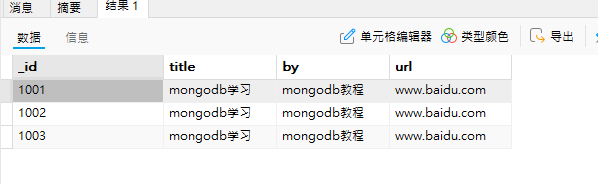
//删除第一个'by'为'mongodb教程'的第一个文档
db.student.remove(
{by:'mongodb教程'},
{justOne: true}
)
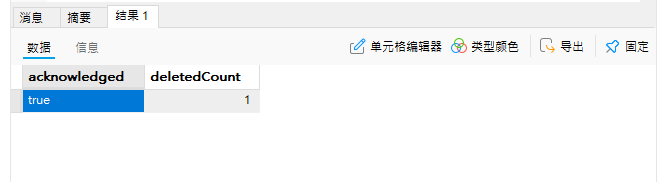
删除后的集合变为(使用find进行查询 db.student.find( ))

可以看到第一个文档被删除了,还有另一种写法你还记得吗?
//删除集合中'by'为'mongodb教程'的所有文档
db.student.remove({by:'mongodb教程'})

使用db.student.find( )查看集合的文档
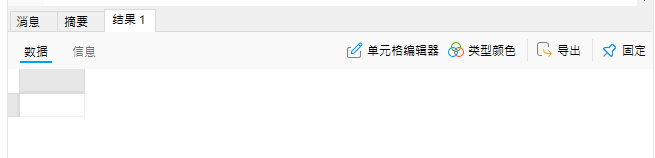
可以看到集合中’by’为’mongodb教程‘的所有文档已经被删除了。这里也还有一种写法是否还有印象呢?
db.student.update({_id:'1001'},
{ $set:
{
title: 'mongo'
}
},{multi:false} //可写可不写,_id值唯一
)
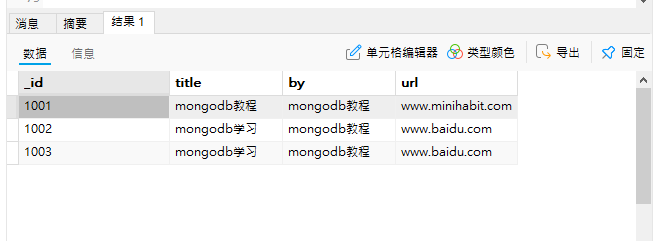
db.student.find() //查看修改后的结果
2.3修改文档
MongoDB 使用 update() 方法来更新集合中的文档。
旧语法:
db.集合名.update(
{},
{ $set: { : , ... } },
{
upsert: ,
multi: ,
}
) :这是 MongoDB 的查询条件,用来指定需要更新的文档。只有符合这个查询条件的文档会被更新。 :这是更新操作,指定了如何修改文档。它通常包含更新操作符,如 $set用于设置指定字段的值。- upsert:这是一个可选的布尔值参数。如果设置为
true,并且查询没有匹配到任何文档,MongoDB 将插入一个新文档。这个新文档将包含update操作指定的字段。 - multi:这也是一个可选的布尔值参数。如果设置为
true,update操作将更新所有匹配查询条件的文档。如果设置为false(默认值),则只更新匹配查询条件的第一个文档。
示例:修改下列student集合中 ‘_id’ 为 ‘1001’ 所对应文档的 ‘title’ 为”mongo”
db.student.update({_id:'1001'},
{ $set:
{
title: 'mongo'
}
},{multi:false} //可写可不写,_id值唯一
)
db.student.find() //查看修改后的结果
新语法:
update 方法用于修改已存在的文档。你可以使用条件来指定哪些文档需要被更新,并且可以指定更新的具体内容。
有两种形式的 update 方法:
updateOne():更新匹配条件的第一个文档。updateMany():更新所有匹配条件的文档。
注意:如果没有符合查询条件的文档,则不会发生变化,不会进行修改操作。如同旧语法,添加 upsert:true 则会自动根据更新的语句,添加新文档,字段名和值即为更新语句的字段。
使用 updateOne() 更新单个文档:
db.集合名.updateOne(
{ }, // 查询条件
{ $set: { : , ... } } // 更新操作
) 使用 updateMany() 更新多个文档:
db.集合名.updateMany(
{ },
{ $set: { : , ... } }
) 这里的
示例:student集合中有以下文档
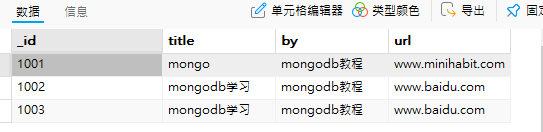
现在修改 ‘_id’ 为:’1005′ 所在文档的 ‘title’ 、’url’字段为’betterManchester’、’betterManchester-CSDN博客betterManchester-CSDN博客betterManchester-CSDN博客‘
我们从集合中可以看到并没有 ‘_id’为’1005’的文档,我们使用updateOne( ),进行修改操作,会发生什么呢?
不添加upsert:true
db.student.updateOne(
{_id:'1005'}, //
{ $set: //
{
title: 'betterManchester',
url:'https://blog.csdn.net/qq_59611575?type=blog'
}
}
)
db.student.find() //查看集合
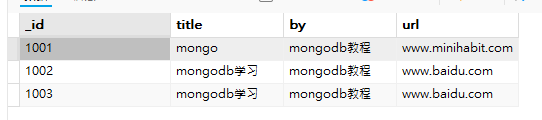
可以看到,不使用 upsert:true,则无法成功的修改信息,因为不存在 ‘_id’ 为’1005’的文档,同时也不会自动添加这个不存在的文档。
添加upsert:true
db.student.updateOne(
{_id:'1005'}, //
{ $set: //
{
title: 'betterManchester',
url:'https://blog.csdn.net/qq_59611575?type=blog'
}
} ,
{
upsert: true, // 如果没有找到匹配的文档,则插入新文档
}
)

db.student.find() //查看当前集合
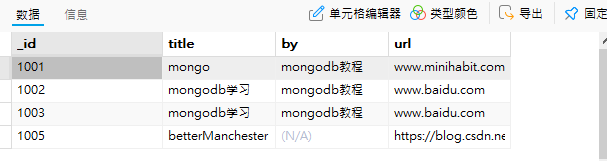
从图可以看到,虽然没有查到符合条件的数据,但是却自动插入了新的文档。
如果使用update( )方法会怎么样呢?
2.4 查询文档
(1)基本查询
使用 find() 方法来查询文档。如果没有指定查询条件,则返回集合中的所有文档:
db.集合名.find(); // 查询集合中所有文档
(2)查询特定文档
使用查询条件来过滤文档
db.集合名.find({ }) 例如:
db.collection.find({ name: "John Doe" }); // 查询 name 字段为 "John Doe" 的文档
(3)查询并投影
使用投影来指定返回的字段,_id 字段默认总是返回,但可以通过设置 { _id: 0 } 来排除它:
0表示不返回字段,1表示返回字段,
db.集合名.find({}, {返回字段}) 示例:以下为student集合,有四个文档,现在让我们查询字段 ‘title’ 为 ‘betterManchester’ 的文档,并投影只返回 ‘url’ 字段

db.student.find(
{title:'betterManchester'}, //查询'title' 为 'betterManchester'的文档
{_id:0,url:1} //设置只投影返回url字段
)
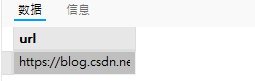
我们可以看到,只返回了 ‘url’ 字段内容,要注意的是,’_id’字段会默认返回,而此题不需要返回,因此设置 ‘_id :0’排除它,让其不返回的。
(4)限制查询结果数量
使用 limit() 方法来限制返回的文档数量:
db.集合名.find().limit(返回文档的数量)示例:返回下列student集合的前三个文档
db.student.find().limit(3); // 只返回前 3 个文档
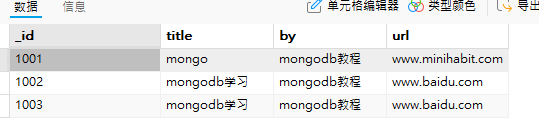
(5)排序结果
使用 sort() 方法对结果进行排序:
按一个字段排序:
db.集合名.find().sort({ 字段:1或-1 })多个字段排序:
db.集合名.find().sort({ 字段1:1或-1,字段2:1或-1,... })1表示升序,-1表示降序。
注意:可以写多个字段,若第一个字段比较完全一致后,则在比较第二个,以此类推。
示例:以下列student集合为例,让其按照 ‘_id’进行降序排序

db.student.find().sort({_id:-1}) //按照'_id'降序排序
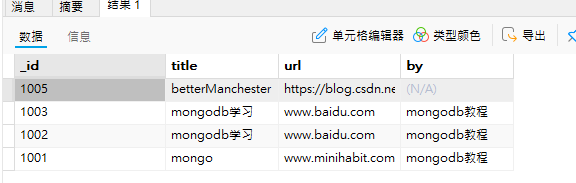
(6)单文档查询
findOne() 方法与 find() 类似,但它只返回匹配条件的第一个文档:
db.集合名.findOne({key:'value'})例如:
db.collection.findOne({ status: "active" })
// 查询字段status为 "active" 的第一个文档
(7)使用正则表达式查询
使用正则表达式来执行模式匹配查询:
db.集合名.find({ key: /正则表达式/i }) //i为不区分大小写示例:下列是一些可能用得到的正则表达式,其余的可以补充学习
db.collection.find({ name: /doe$/i })
// 查询以 "doe" 结尾的 name 字段,不区分大小写// 查找任何包含 'test' 的文档
db.collection.find({ field: /test/ });
// 查找以 'test' 开头的文档
db.collection.find({ field: /^test/ });
// 查找以 'test' 结尾的文档
db.collection.find({ field: /test$/ });
(8)范围查询
查询某个字段在一定范围内的文档:
db.集合名.find({ key: { $gt: value1, $lt: value2 } })
//value1为最小值,value2为最大值 选取 大于value1,小于value2的文档示例:有如下列的student集合,现在查询 ‘num’ 大于2小于8的文档

db.student.find(
{
num:{$gt:2,$lt:8}
}
)
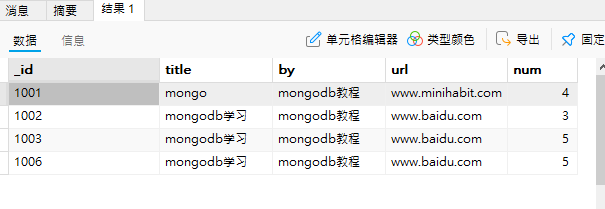
(9)空值查询
查询字段值为 null 的文档:
db.集合名.find({ key: { $eq: null } })示例:
db.collection.find({ age: { $eq: null } }); // 查询 age 字段为 null 的文档三.聚合
MongoDB 的聚合框架允许你执行复杂的数据处理和分析操作。聚合操作使用管道处理数据,每个管道阶段执行特定的操作,如过滤、排序、分组等。一般用不上,重点为分组、聚合表达式和连表操作
3.1分组($group)
语法格式:
db.集合名.aggregate([
{ $group: { _id: "$key1" } }
]);这个 MongoDB 聚合管道操作使用了 $group 阶段,它的作用是将集合 中的文档按照 key 字段的值进行分组。
示例:以下名为student的集合,现在按照字段’by’分组

db.student.aggregate([
{
$group:{
_id:"$by"
}
}
])

3.2聚合表达式
在 MongoDB 中,聚合框架提供了多种聚合表达式来执行诸如求和、平均值、最大值、最小值等计算,这里对第一个求和语法进行描述,后面几个表达式写法都类似,因此直接写的示例。
聚合表达式语法格式:
db.集合名.aggregate([
{ $group: { _id: key, key2: { $操作: "$key3" } } }
]);key为分组的字段值,可以写为null。
key3为所选的求和的字段.
key2为对所选key3字段进行求和和新生成字段的名字。
$后接操作,如求和$sum,求最大值$max等等。
(1)求和($sum)
计算一个字段的所有值的总和。
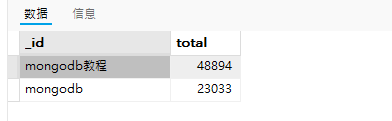
示例:以下是student集合的文档信息,下面将其通过’by’字段进行分组,然后对’tuition_fee’字段进行求和。
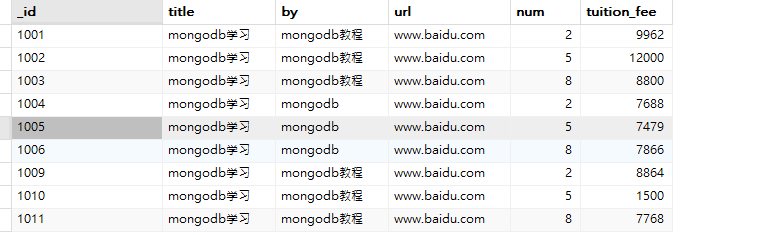
db.student.aggregate([
{
$group:{
_id:'$by',
total:{ $sum:'$tuition_fee'}
}
}
])
(2)平均值($avg)
根据’by’字段进行分组,计算一个字段的所有值的平均值。
db.collection.aggregate([
{ $group: { _id: '$by', average: { $avg: "$num" } } }
]);(3)最大值($max)
不根据字段分组,找出一个字段的最大值。
db.collection.aggregate([
{ $group: { _id: null, maxPrice: { $max: "$tuition_fee" } } }
]);(4)最小值($min)
不根据字段分组,找出一个字段的最小值。
db.collection.aggregate([
{ $group: { _id: null, minPrice: { $min: "$tuition_fee" } } }
]);(5)计数($count)
根据’url’字段进行分组,计算分组中文档的数量。
db.collection.aggregate([
{ $group: { _id: "$url", count: { $count: {} } } }
]);3.3 联合操作
在 MongoDB 中,连表查询通常指的是将两个或多个集合(类似于关系数据库中的表)的数据根据一定的关联条件合并起来的操作。MongoDB 没有传统关系数据库中的 JOIN 操作,但是可以通过聚合管道中的 $lookup 阶段来实现类似的功能。
$lookup 阶段可以执行左连接、内连接和外连接等操作,它允许你从另一个集合或者同一个集合中的不同字段中拉取数据,并将结果合并到一个单一的文档中。
在 MongoDB 的聚合框架中,$project 阶段用于指定输出的文档格式,包括哪些字段应该显示、隐藏或添加计算字段。这个阶段非常灵活,可以用来重塑文档结构,进行字段的添加、删除和修改。这个建议配合后面的示例练习理解。
语法格式:
db.collection.aggregate( //当前表A
[
{
'$lookup':
{
"from": "task_collection", #需要联合查询的另一张表B
"localField": "task_id", #表A的字段
"foreignField": "task_id", #表B的字段
"as": "task_docs" #根据A、B联合生成的新字段名
},
},
//以下代码根据情况写,可以省略
{
'$project': #联合查询后需要显示哪些字段,1:显示
{
'task_docs.task_id':1,
'task_docs.task_name':1,
'task_docs.task_type':1,
'task_docs.evidence_content':1,
'case_id':1,
'task_id':1,
'user_id':1,
'_id':0,
},
}
]
)在 $project 阶段,你可以指定字段的包含(1)或排除(0),以及如何显示它们:
- 包含字段:如果你想包含一个字段,可以直接指定字段名或设置为 1。
- 排除字段:如果你想排除一个字段,可以设置为 0。
- 添加计算字段:你可以添加新的字段,并为其指定计算后的值。
示例:假设你有两个集合:orders 和 customers。orders 集合包含客户的订单信息,其中包括一个 customerId 字段,用于引用 customers 集合中的客户。你想要获取所有订单及其对应客户的详细信息。

集合 customers

集合 orders
对前面进行复习,这里展示如何创建集合orders和customers
//创建两个集合并插入文档
var order=[
{
"_id": "order1",
"customerId": "customer1",
"product": "Widget",
"quantity": 2,
"price": 19.99
},
{
"_id": "order2",
"customerId": "customer2",
"product": "Widget",
"quantity": 3,
"price": 29.99
}
]
db.orders.insert(order) //创建orders集合
var customer= [
{
"_id": "customer1",
"name": "John ",
"email": "[email protected]",
"status": "active"
},
{
"_id": "customer2",
"name": "John Doe",
"email": "[email protected]",
"status": "active"
}
]
db.customers.insert(customer) //创建orders集合
//对两个集合进行联合查询
db.orders.aggregate([
{
$lookup: {
from: "customers", // 要连接的集合名称
localField: "customerId", // 订单集合中的字段
foreignField: "_id", // 客户集合中的字段
as: "customerDetails" // 输出的数组字段名称
}
}])

联合的集合存储在’customerDetails’数组中,点击这个字段,我们就能看到对应的文档字段及字段值。那么,我们如何实现直接展示联合集合的字段呢?需要使用 $project进行操作。
db.orders.aggregate([
{
$lookup: {
from: "customers", // 要连接的集合名称
localField: "customerId", // 订单集合中的字段
foreignField: "_id", // 客户集合中的字段
as: "customerDetails" // 输出的数组字段名称
}
},
{
$project: { //联合查询后需要显示哪些字段:1表示显示
_id: 1,
product: 1,
quantity: 1,
price: 1,
customerName: "$customerDetails.name", // 从客户详情中提取客户名称
customerEmail: "$customerDetails.email" ,// 从客户详情中提取客户电子邮件
Status:"$customerDetails.status" //从客户详情中提取客户状态
}
}
]);

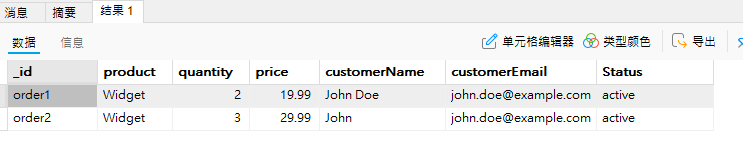
从上述文档,我们可以看到联合的字段已经展示了,’name’字段修改为’customerName’,”email字段改为’customerEmail’,’status’改为’Status’字段进行展示,但是,字段值依然是属于引用类型,点击进去才能知道对应的值,如何让字段值进行展示呢?需要使用$unwind将 customerDetails 数组展开为单独的文档。
db.orders.aggregate([
{
$lookup: {
from: "customers", // 要连接的集合名称
localField: "customerId", // 订单集合中的字段
foreignField: "_id", // 客户集合中的字段
as: "customerDetails" // 输出的数组字段名称
}
},
{
$unwind: "$customerDetails" // 将 customerDetails 数组展开为单独的文档
},
{
$project: { //联合查询后需要显示哪些字段:1表示显示
_id: 1,
product: 1,
quantity: 1,
price: 1,
customerName: "$customerDetails.name", // 从客户详情中提取客户名称
customerEmail: "$customerDetails.email" ,// 从客户详情中提取客户电子邮件
Status:"$customerDetails.status" //从客户详情中提取客户状态
}
}
]);
评论(0)