引言
文章目录
一、朴素贝叶斯网络
朴素贝叶斯网络是一种特殊的贝叶斯网络,它假设网络中的所有变量(特征)在给定类变量(目标变量)的条件下都是条件独立的。这种假设使得网络结构非常简单,每个特征节点都直接连接到类节点,而特征节点之间没有连接
1.1 基本概念
1.1.1 节点
- 类节点(Class Node):表示要预测的变量或类别
- 特征节点(Feature Nodes):表示用于预测类节点的各个特征
1.1.2 边(Edges)
- 从类节点指向每个特征节点的有向边,表示类节点对特征节点的影响
1.1.3 条件独立性
- 朴素贝叶斯网络假设每个特征节点在给定类节点的情况下都是条件独立的,即特征之间不存在依赖关系
1.2 特点
1.2.1 结构简单
- 由于条件独立性的假设,朴素贝叶斯网络的结构非常简单,每个特征节点仅与类节点有直接联系
1.2.2 易于理解和实现
- 网络的简单结构使得朴素贝叶斯网络容易理解和实现
1.2.3 计算效率高
- 由于特征之间的独立性假设,计算后验概率时只需单独考虑每个特征,从而减少了计算量
1.3 应用
朴素贝叶斯网络广泛应用于各种分类问题,特别是在以下场景中:
- 文本分类:如垃圾邮件检测、情感分析、新闻分类等
- 医疗诊断:根据病人的症状预测疾病
- 推荐系统:根据用户的行为和属性推荐商品或服务
1.4 数学表示
朴素贝叶斯网络的数学基础是贝叶斯定理。给定一个数据点
x
=
(
x
1
,
x
2
,
.
.
.
,
x
n
)
x = (x_1, x_2, …, x_n)
x=(x1,x2,…,xn)和类别
C
C
C,朴素贝叶斯分类器计算后验概率
P
(
C
∣
X
)
P(C|X)
P(C∣X)如下:
P
(
C
∣
X
)
=
P
(
X
∣
C
)
P
(
C
)
P
(
X
)
P(C|X) = frac{P(X|C)P(C)}{P(X)}
P(C∣X)=P(X)P(X∣C)P(C)
由于特征独立性假设,上式可以简化为:
P
(
C
∣
X
)
∝
P
(
C
)
∏
i
=
1
n
P
(
x
i
∣
C
)
P(C|X) propto P(C) prod_{i=1}^{n} P(x_i|C)
P(C∣X)∝P(C)i=1∏nP(xi∣C)
其中,
P
(
C
)
P(C)
P(C) 是类
C
C
C的先验概率,
P
(
x
i
∣
C
)
P(x_i|C)
P(xi∣C)是在类
C
C
C下特征
x
i
x_i
xi的条件概率
1.5 局限性
尽管朴素贝叶斯网络在许多情况下都很有效,但其条件独立性的假设在很多实际问题中并不成立,这可能导致模型性能不如其他不假设特征独立性的模型。然而,由于其实用性和在大量实际应用中的良好表现,朴素贝叶斯网络仍然是机器学习和数据科学中重要的工具之一
二、朴素贝叶斯网络在python中的实例
朴素贝叶斯网络在Python中的实例
2.1 实例背景
朴素贝叶斯网络是一种基于贝叶斯定理的简单概率模型,适用于处理分类问题。在Python中,我们可以使用scikit-learn库来实现朴素贝叶斯网络。以下是一个使用不同数据集的实例——葡萄酒质量分类
2.2 实现步骤
- 数据准备:我们将使用葡萄酒质量数据集,该数据集包含了葡萄酒的各种化学特性及其质量评分
- 数据预处理:对数据进行标准化处理,以便更好地适用于朴素贝叶斯分类器
- 模型训练:使用高斯朴素贝叶斯分类器进行训练
- 模型评估:通过交叉验证来评估模型的性能
2.3 python代码
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.preprocessing import StandardScaler
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import classification_report
# 加载葡萄酒数据集
wine = load_wine()
X, y = wine.data, wine.target
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42)
# 初始化高斯朴素贝叶斯分类器
gnb = GaussianNB()
# 训练模型
gnb.fit(X_train, y_train)
# 评估模型
y_pred = gnb.predict(X_test)
print(classification_report(y_test, y_pred))
# 使用交叉验证评估模型性能
scores = cross_val_score(gnb, X_scaled, y, cv=5)
print(f"交叉验证平均准确率: {scores.mean()}")
输出结果: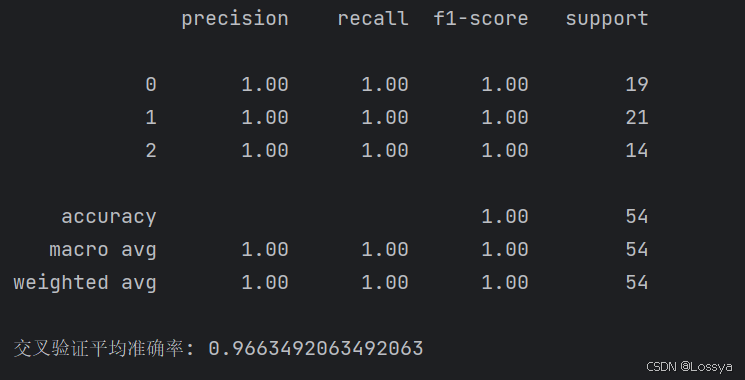
2.4 代码解释
- 首先对数据进行了标准化处理
- 然后使用高斯朴素贝叶斯分类器进行训练和预测
- 最后通过打印分类报告和计算交叉验证的平均准确率来评估模型的性能
- 这种方式不仅展示了朴素贝叶斯网络的应用,还体现了数据处理和模型评估的完整流程
三、概率推断在医疗领域中的使用
概率推断在医疗领域扮演着至关重要的角色,它可以帮助医生和研究人员在不确定性下做出更明智的决策
3.1 概率推断在医疗领域的使用
- 疾病诊断:通过分析病人的症状、实验室检测结果和病史,概率推断可以预测病人患有某种疾病的概率
- 预后评估:预测疾病的发展过程和可能的后果,帮助医生制定治疗计划
- 治疗选择:评估不同治疗方案的效果和潜在风险,为患者提供个性化的治疗方案
- 疾病流行预测:通过监测数据,预测疾病在人群中的传播概率和趋势
3.2 自动化推断的优势
- 速度:自动化系统能够快速处理大量数据,迅速得出推断结果
- 一致性:自动化推断可以提供一致的标准化的决策,减少了人为误差
- 可扩展性:在面对大规模数据时,自动化系统可以轻松扩展以处理更多的案例
- 持续学习:随着更多数据的积累,自动化系统可以通过机器学习不断优化其推断模型
3.3 自动化推断的劣势
- 解释性:自动化系统的推断过程可能不够透明,难以向医生和患者解释推断的依据
- 数据依赖:推断质量高度依赖于输入数据的质量和完整性
- 适应性:自动化系统可能难以适应新的医疗场景或罕见病例
3.4 人类医生的优势
- 专业经验:医生具有丰富的临床经验和直觉,可以在复杂情况下做出判断
- 情境理解:医生能够考虑患者的整体情况,包括心理和社会因素
- 人际交流:医生可以与患者进行有效沟通,提供情感支持和解释决策过程
3.5 人类医生的劣势
- 认知负荷:医生可能因为信息过载而犯错,特别是在疲劳或压力大时
- 不一致性:不同医生可能对同一情况做出不同的推断,导致治疗标准不统一
- 资源限制:医生的时间和精力有限,无法处理大量数据或进行复杂的统计分析
3.6 总结
概率推断的自动化在医疗领域具有巨大的潜力,可以辅助医生做出更准确和高效的决策。然而,它不应完全取代人类医生,而是作为一个辅助工具,结合医生的专业知识和临床经验,共同提升医疗服务的质量和效率
评论(0)